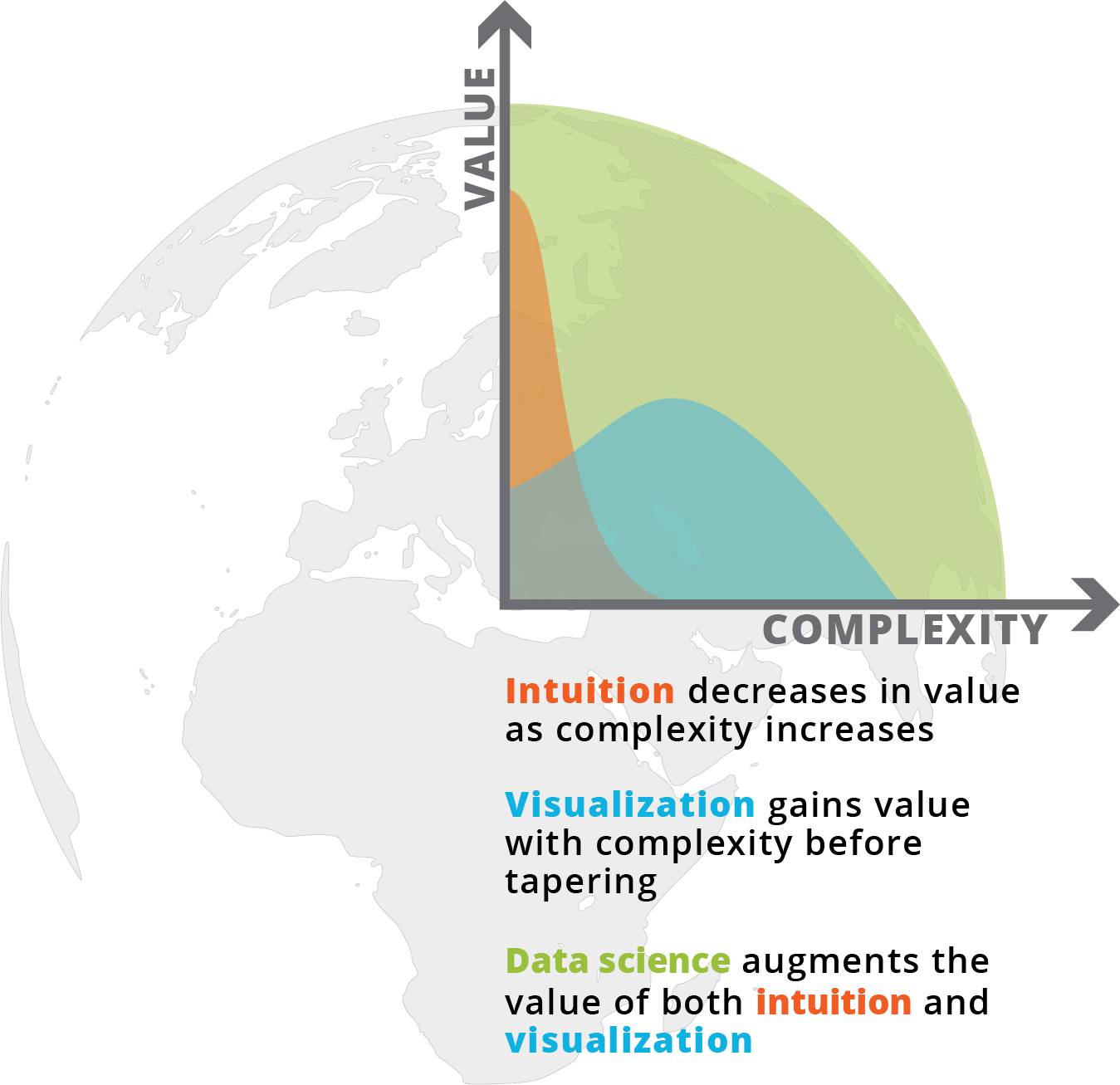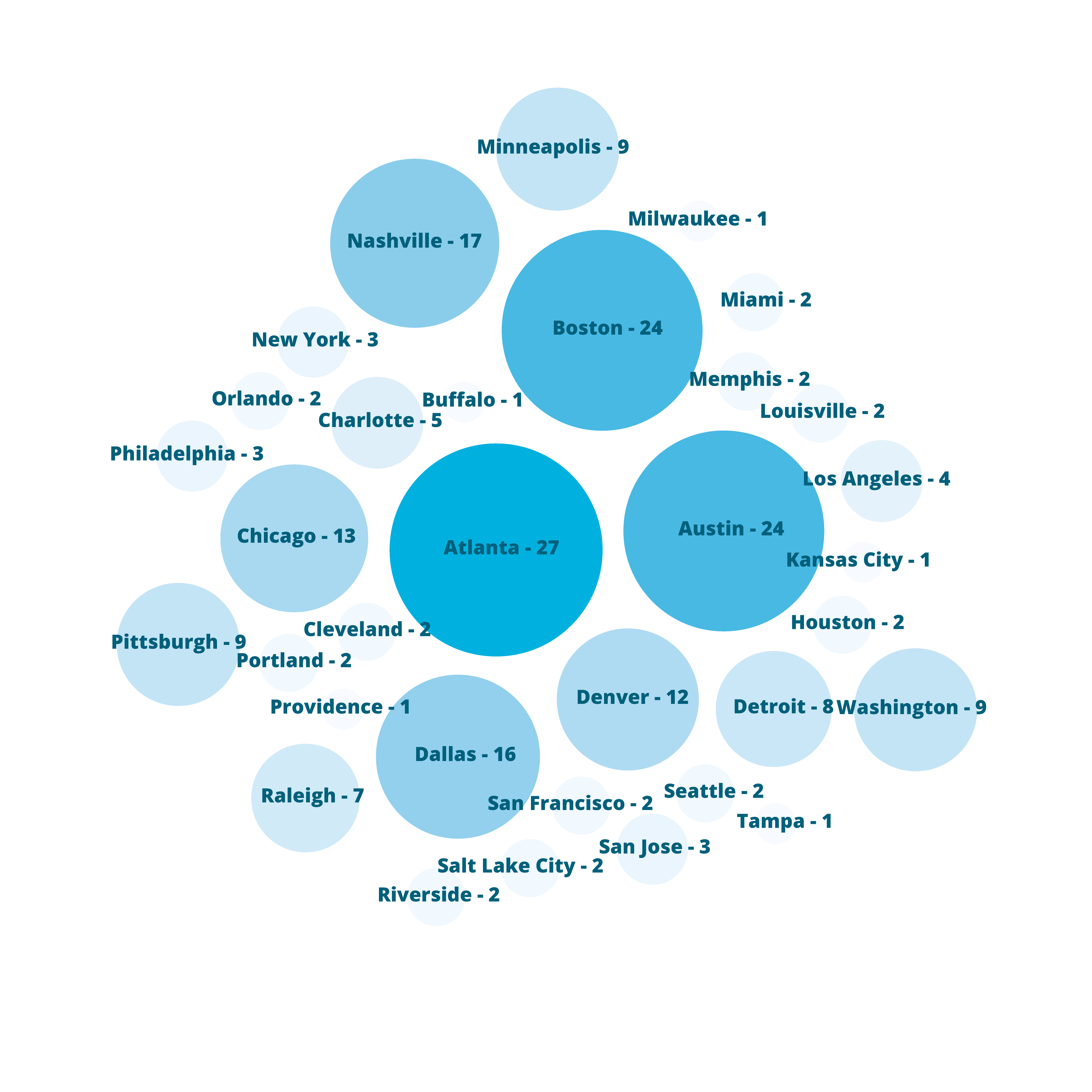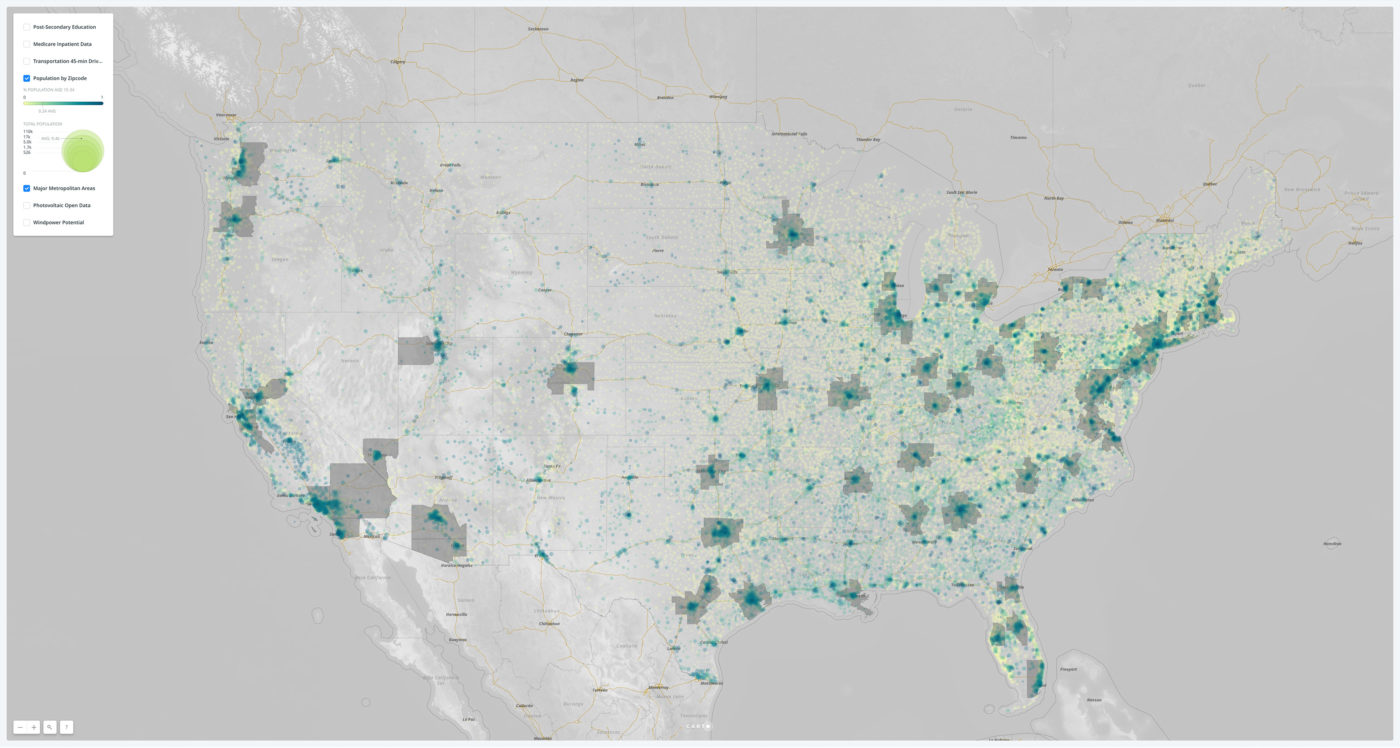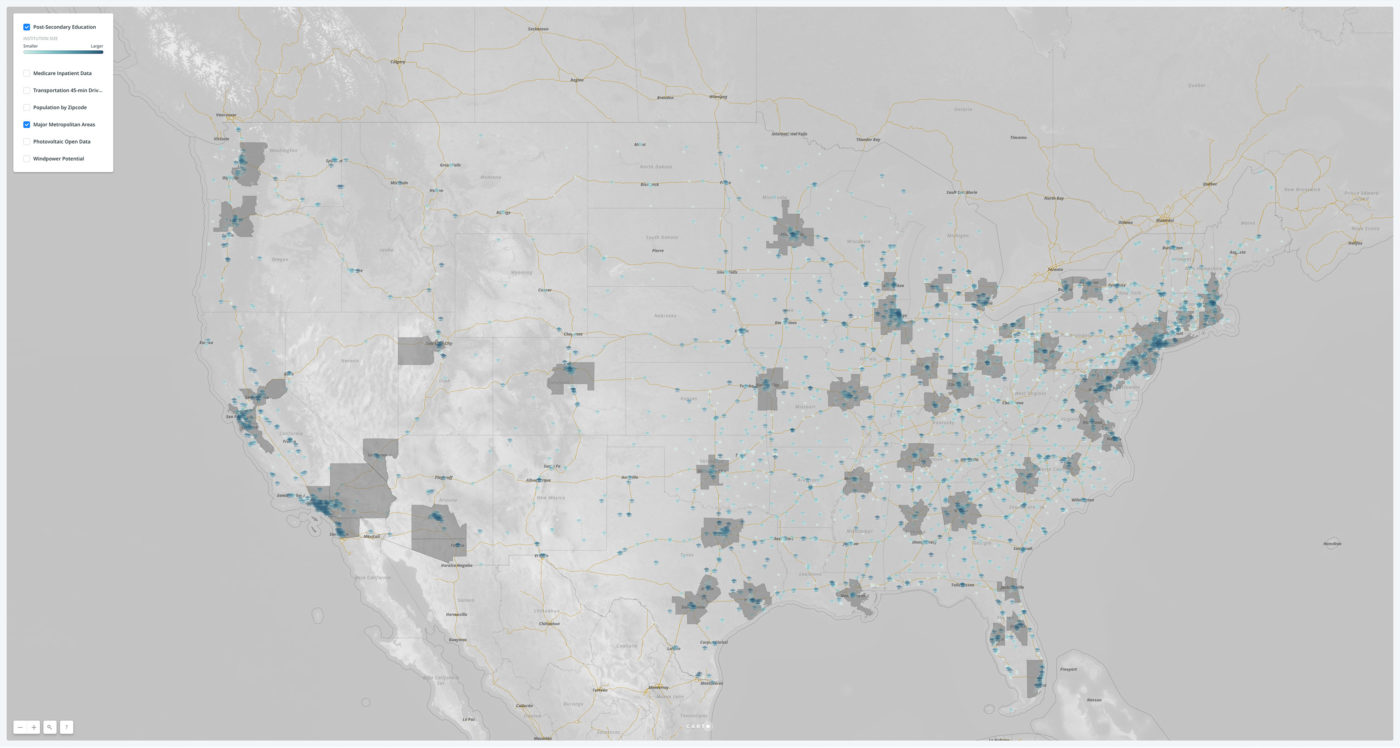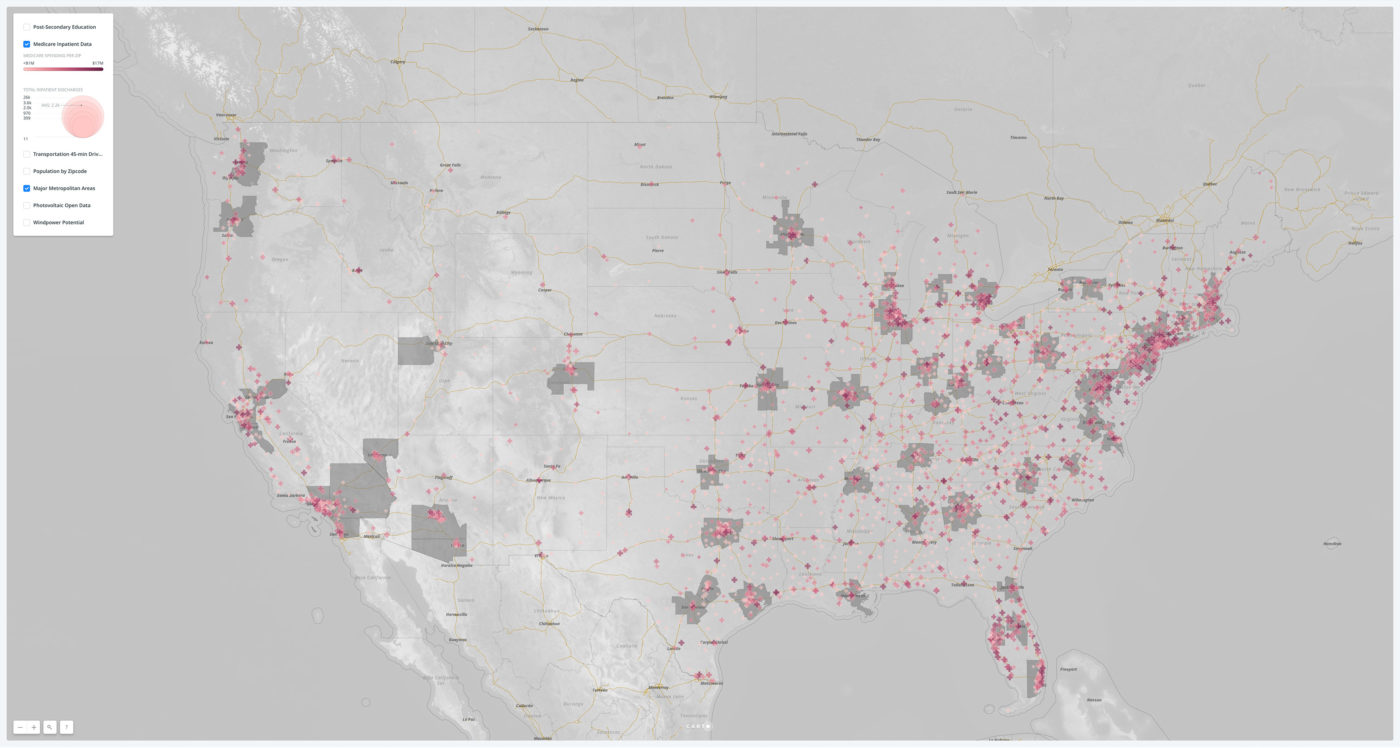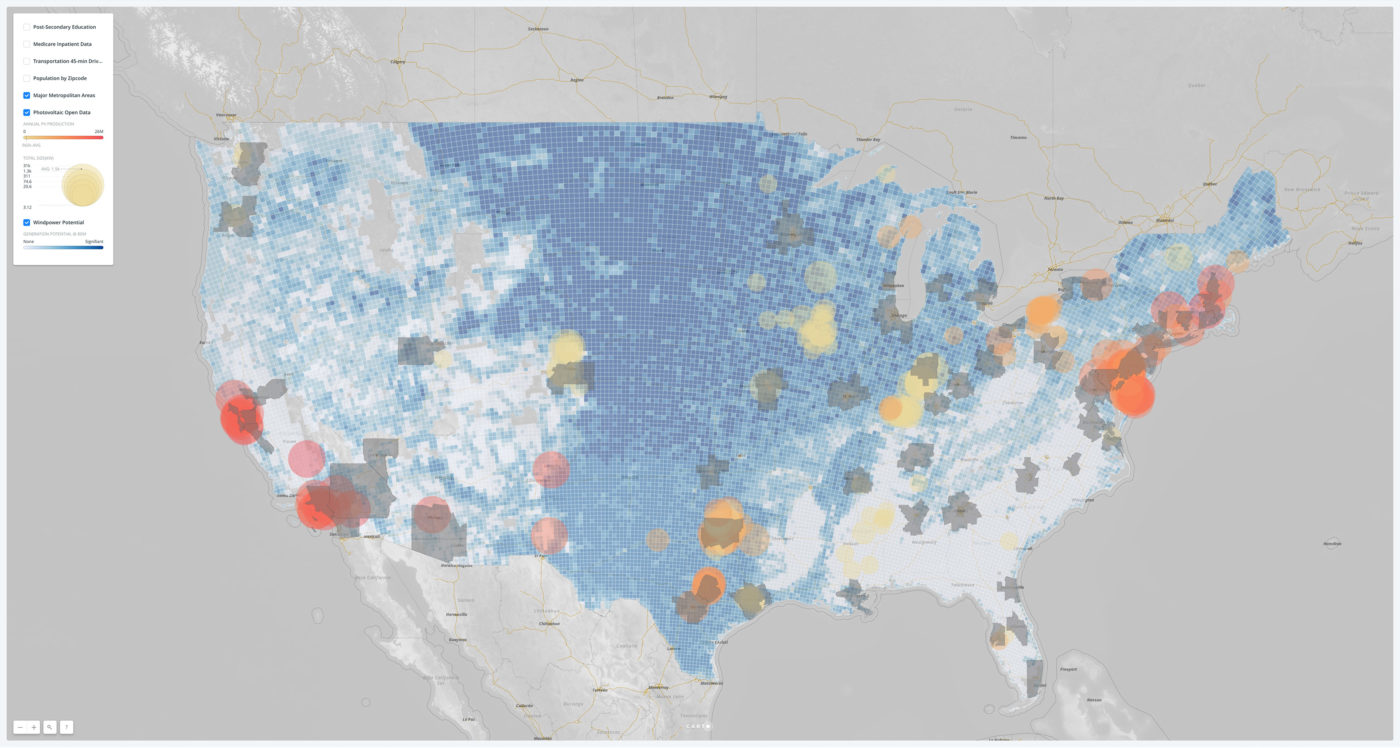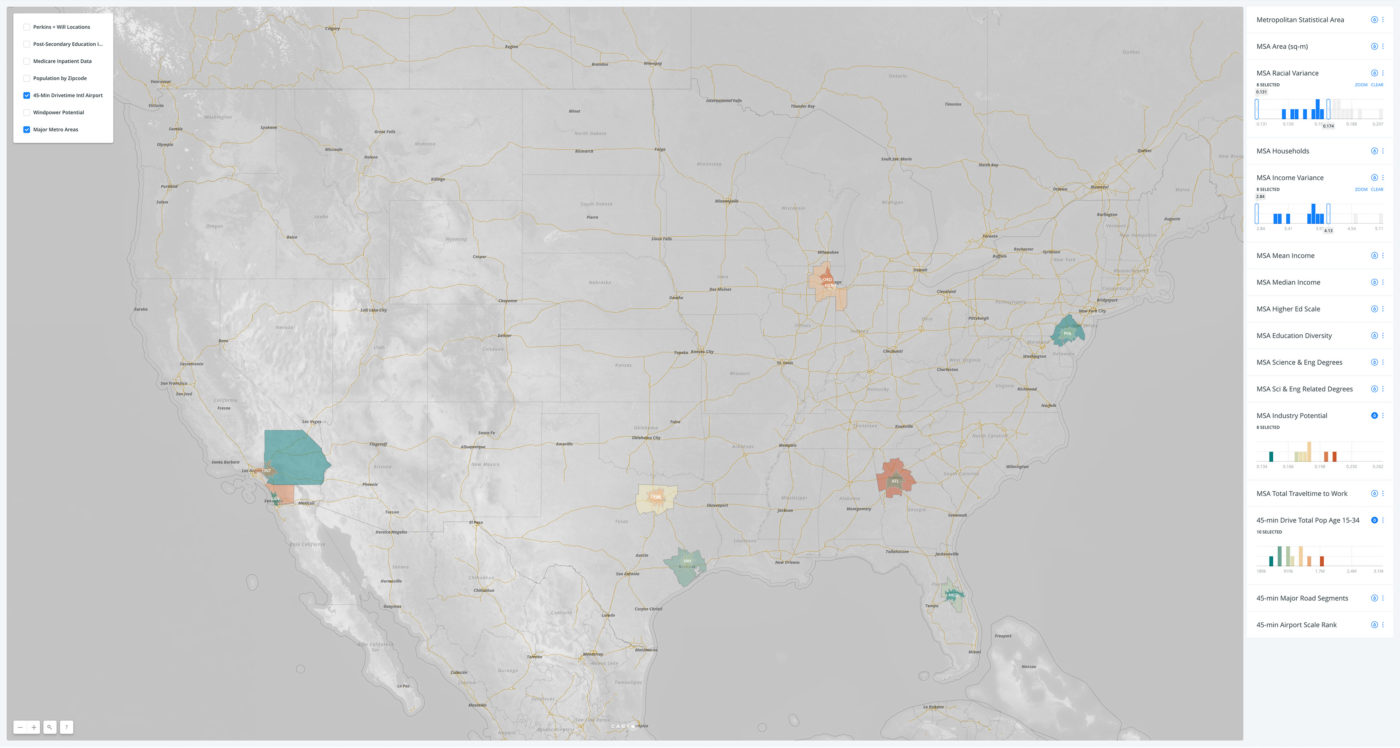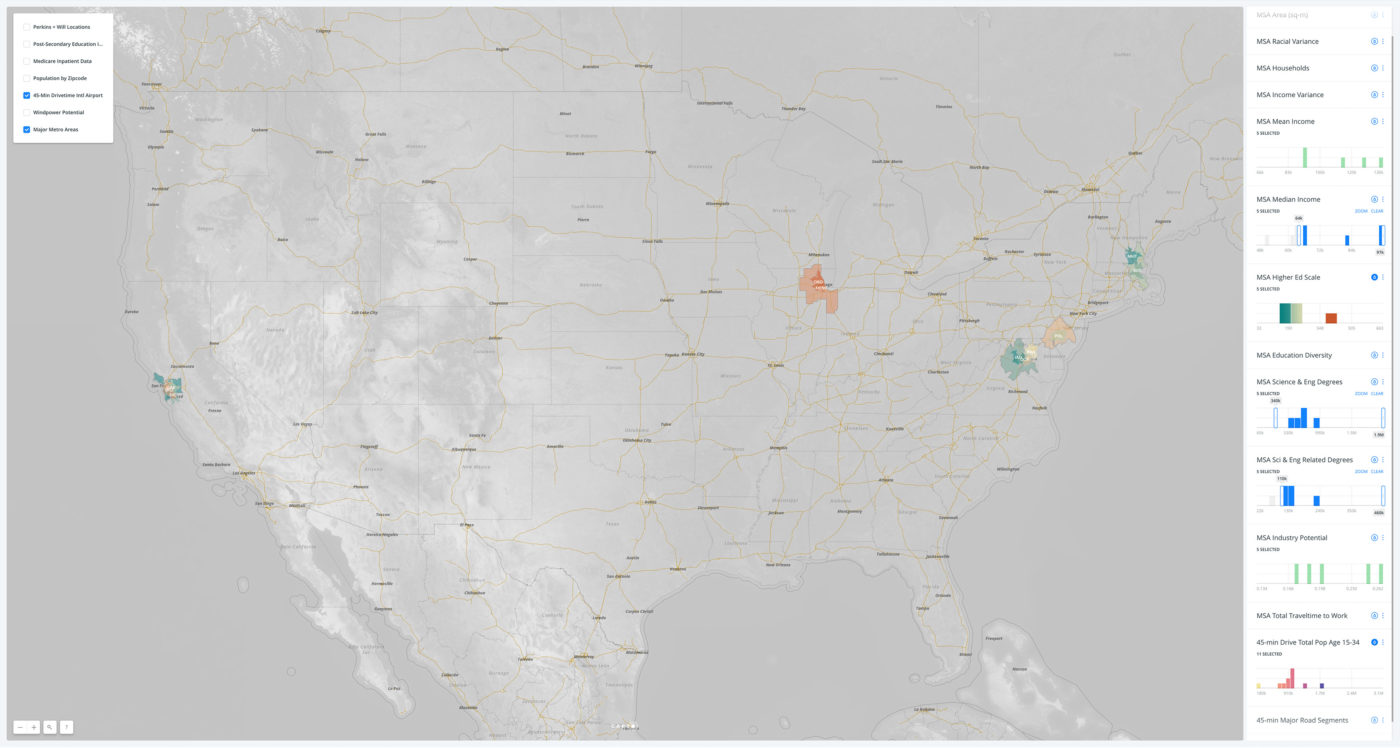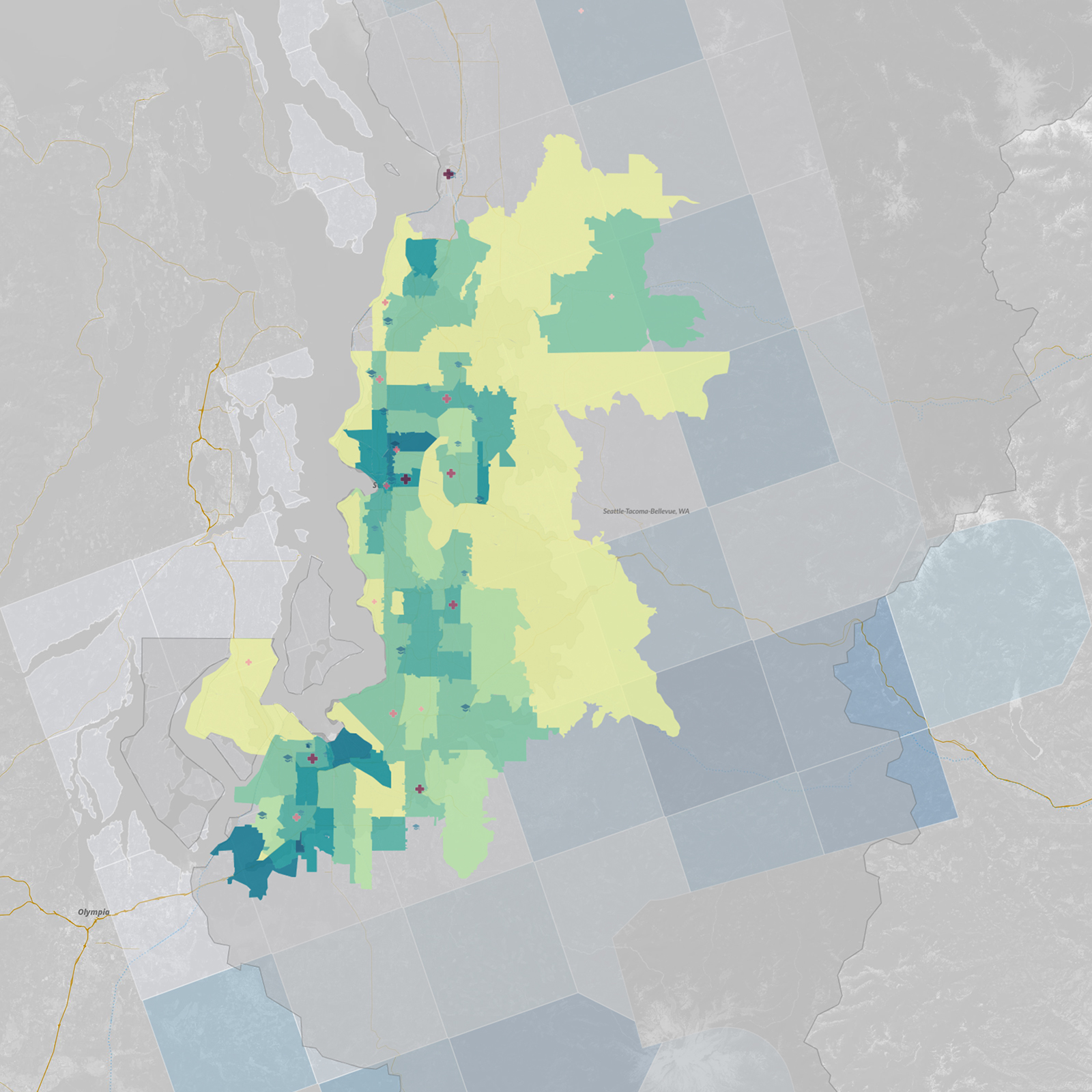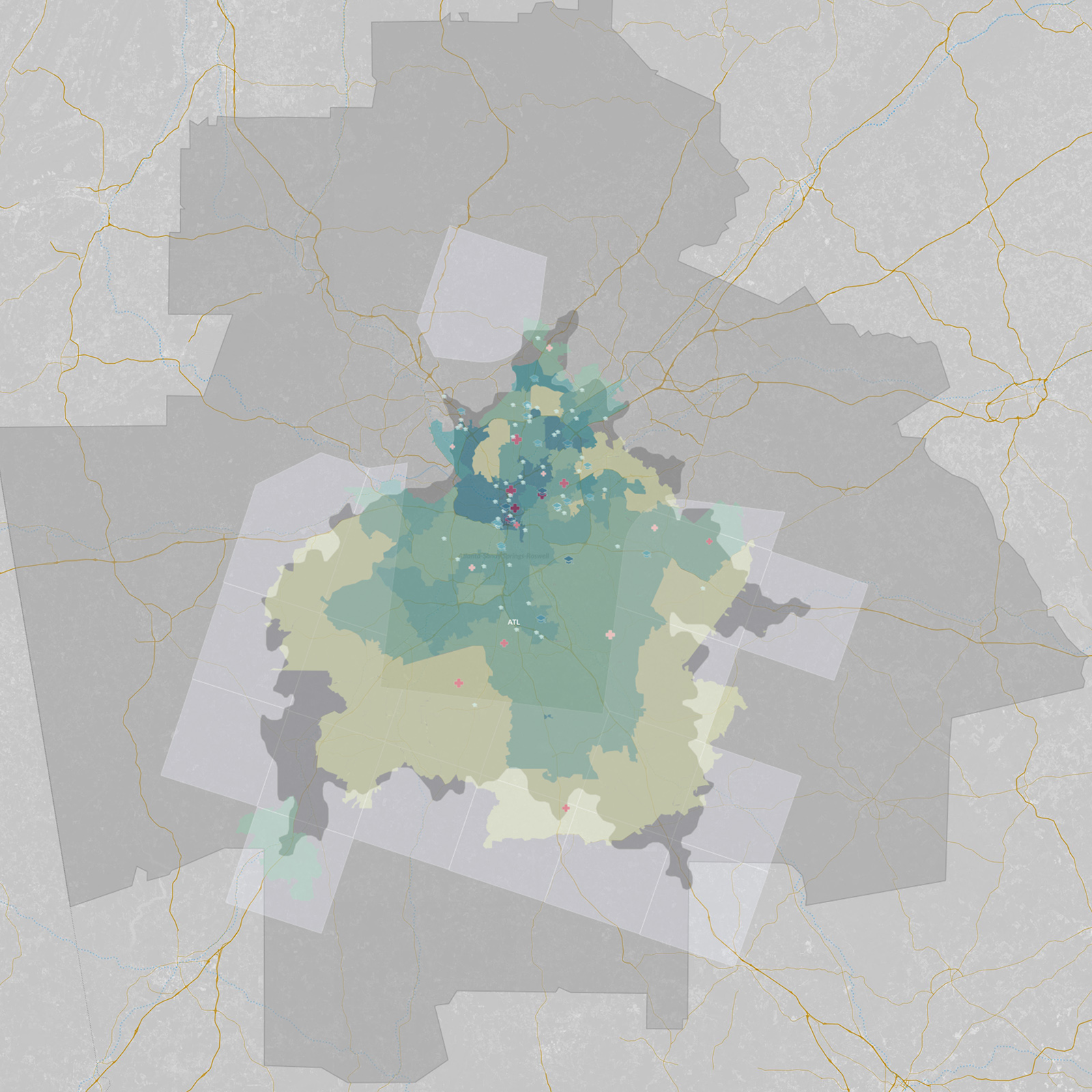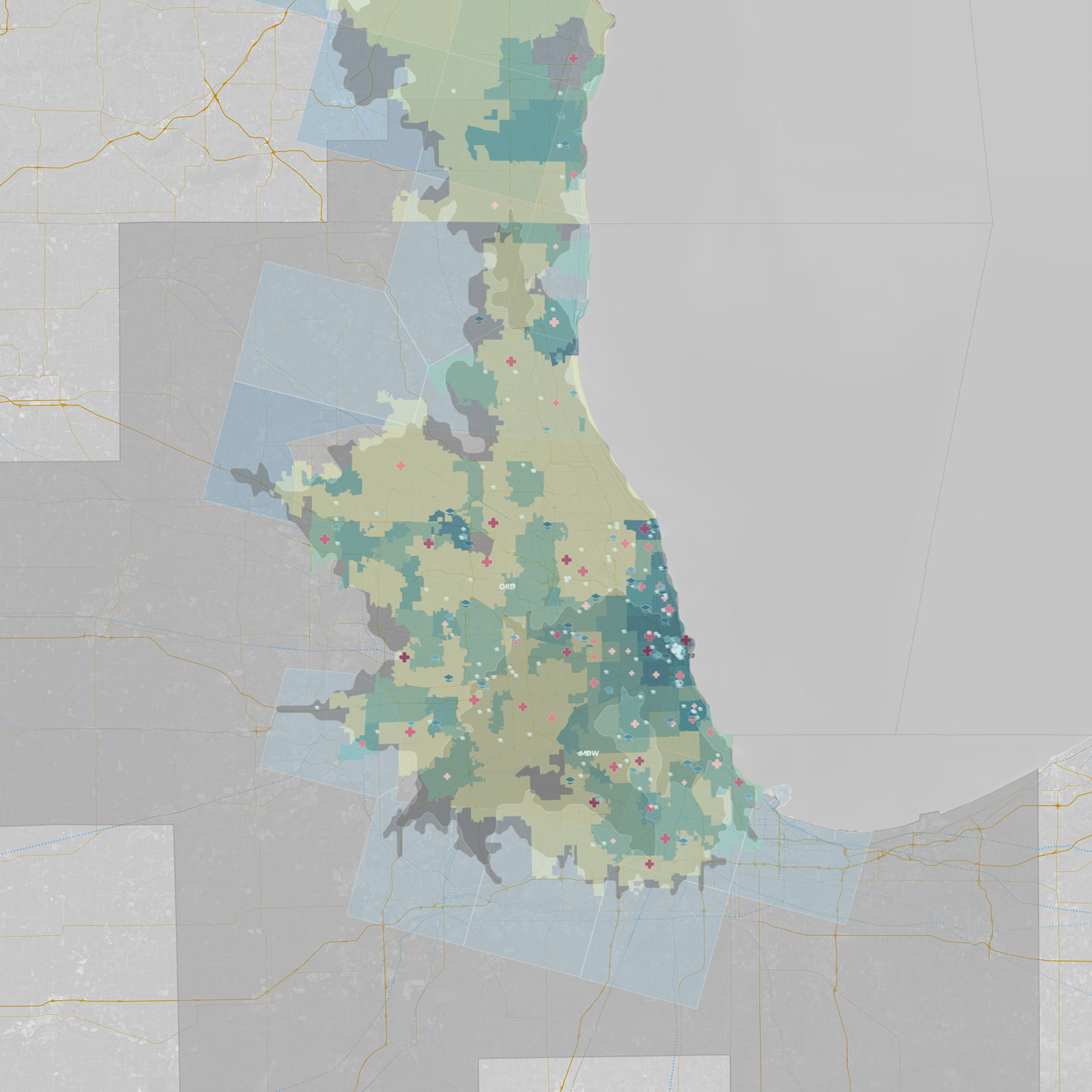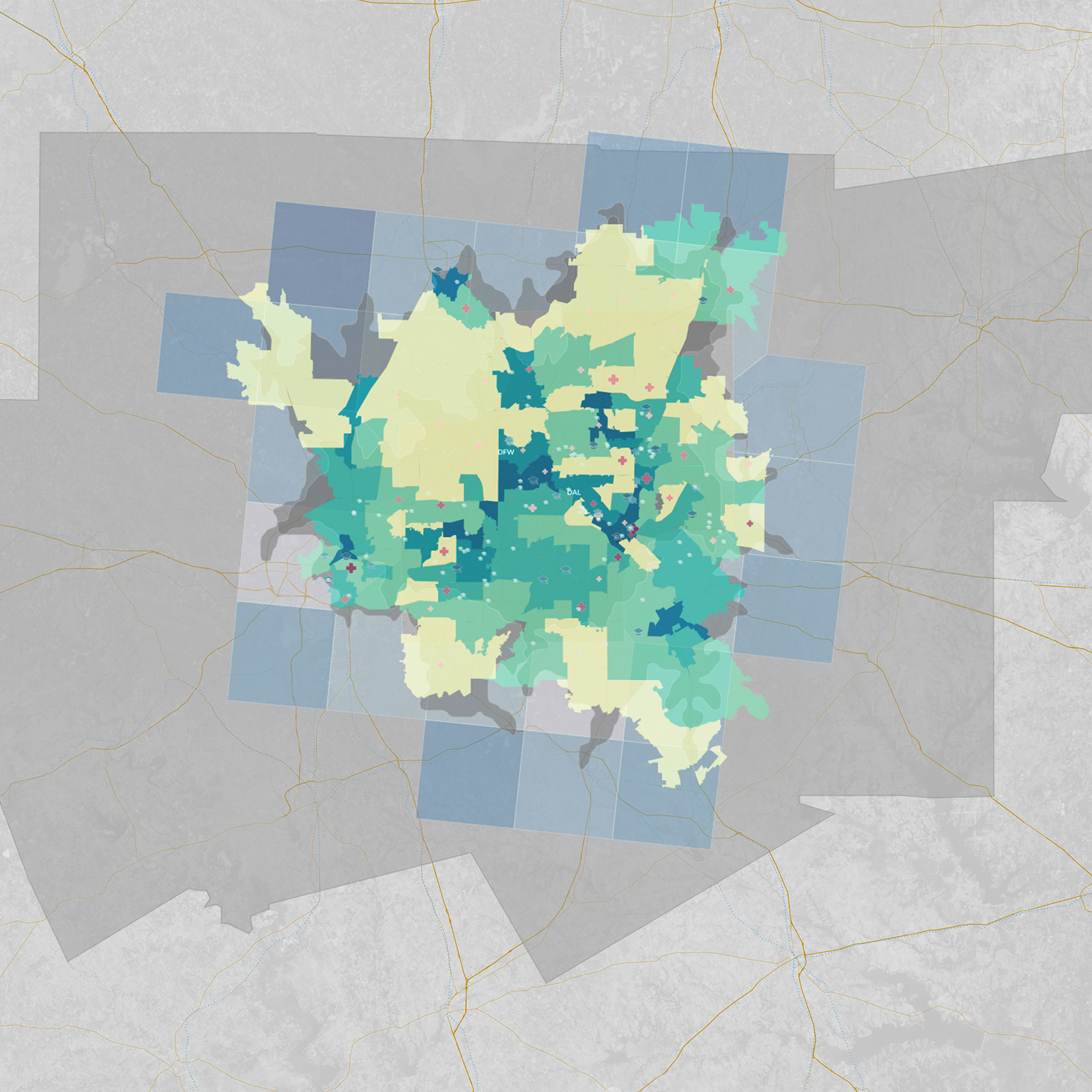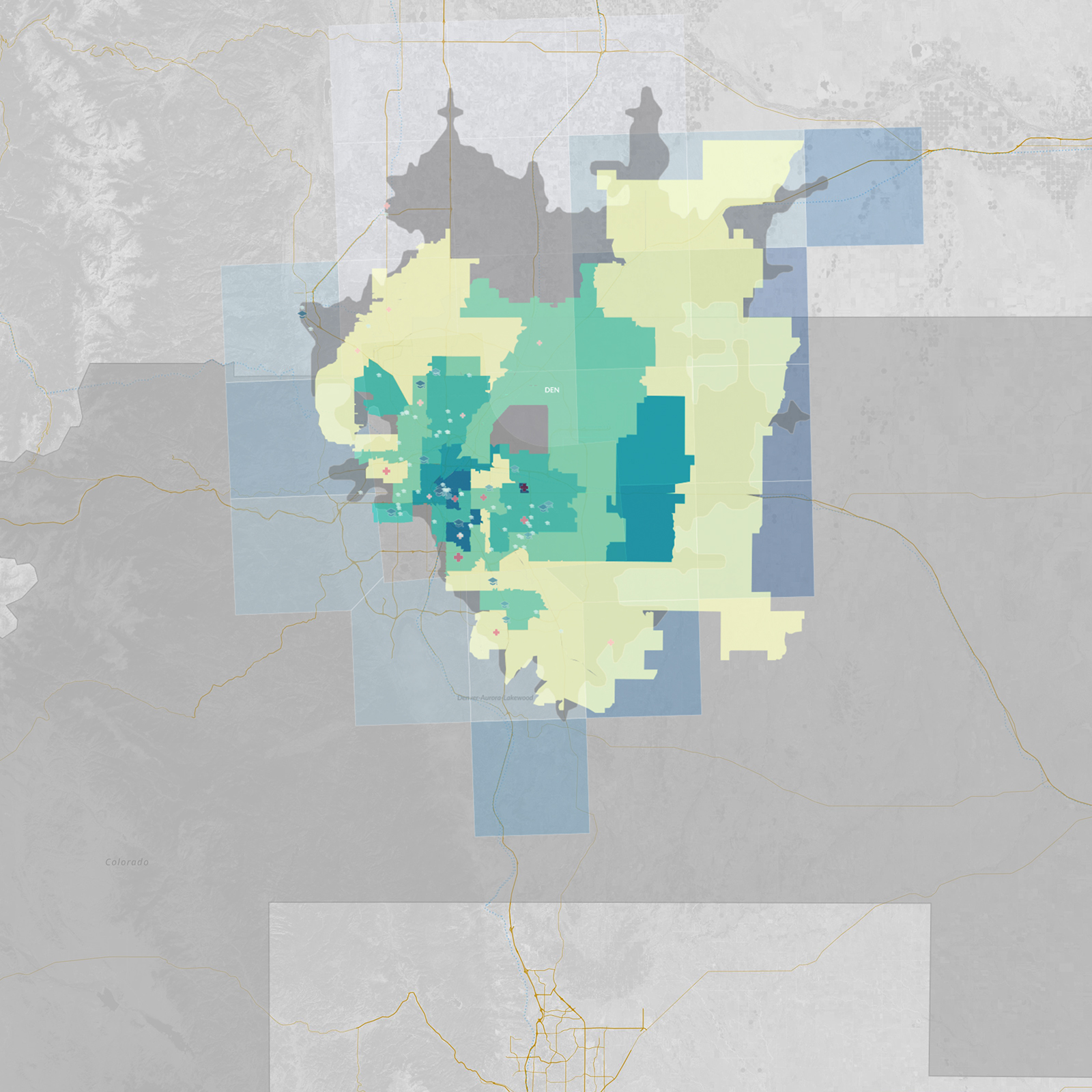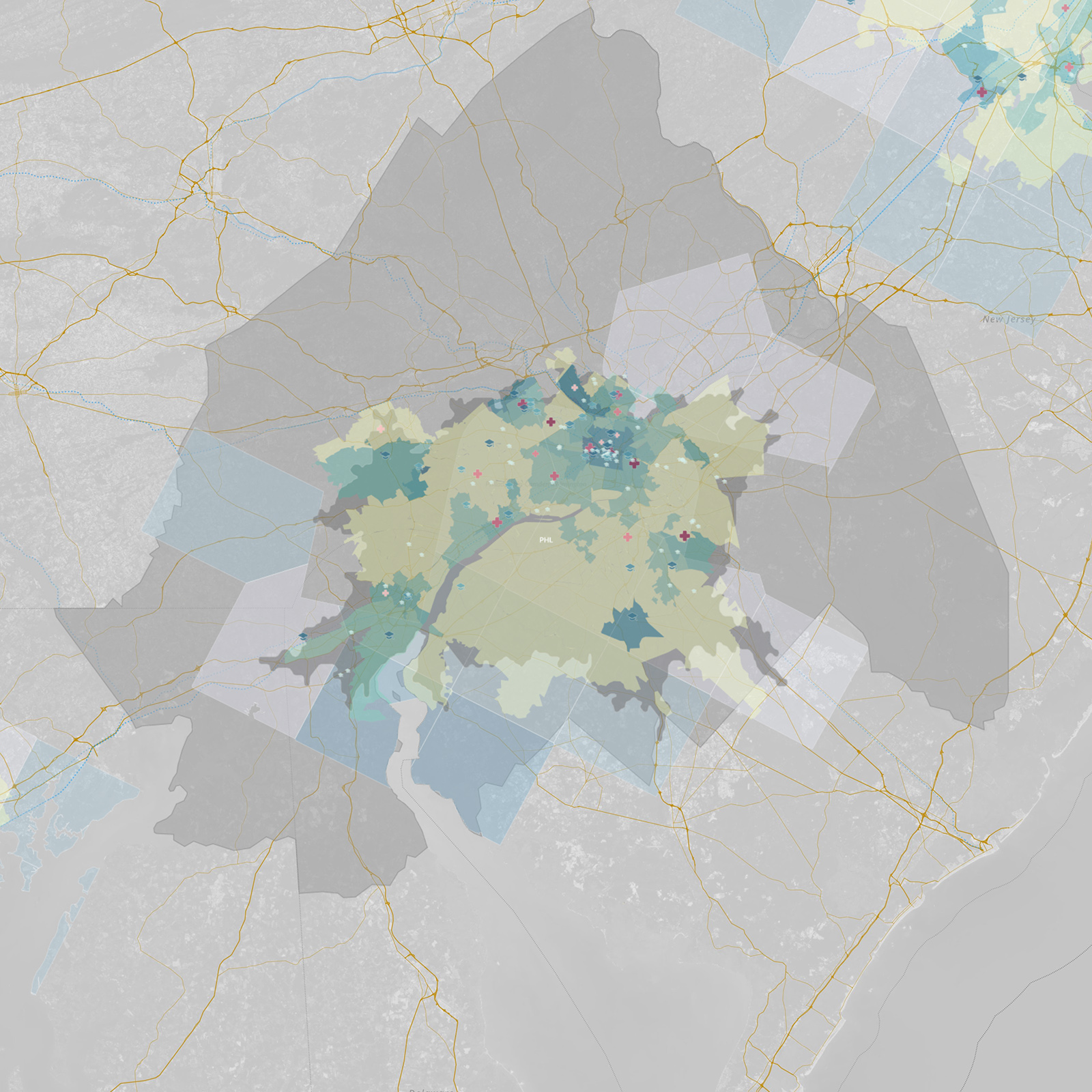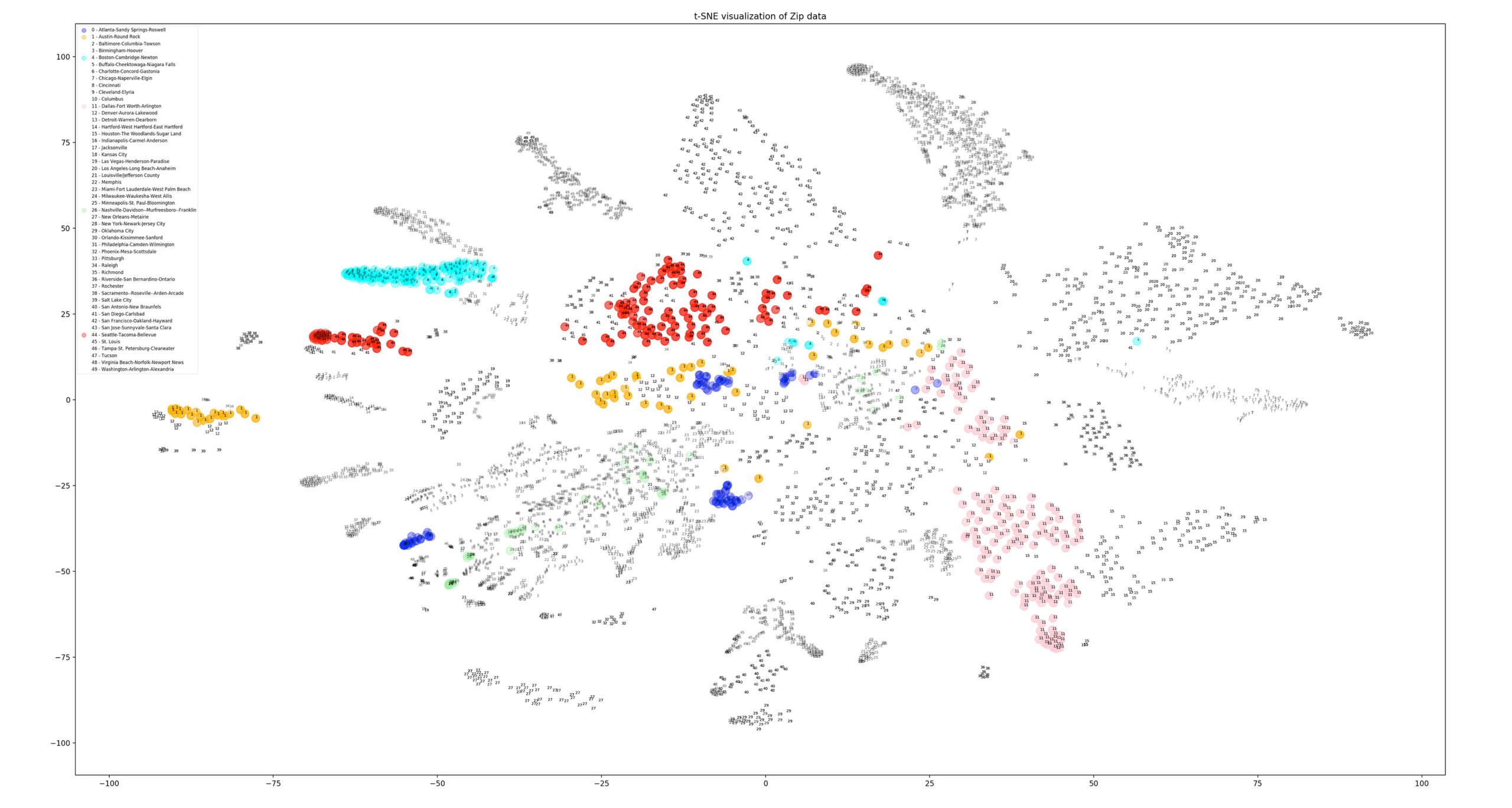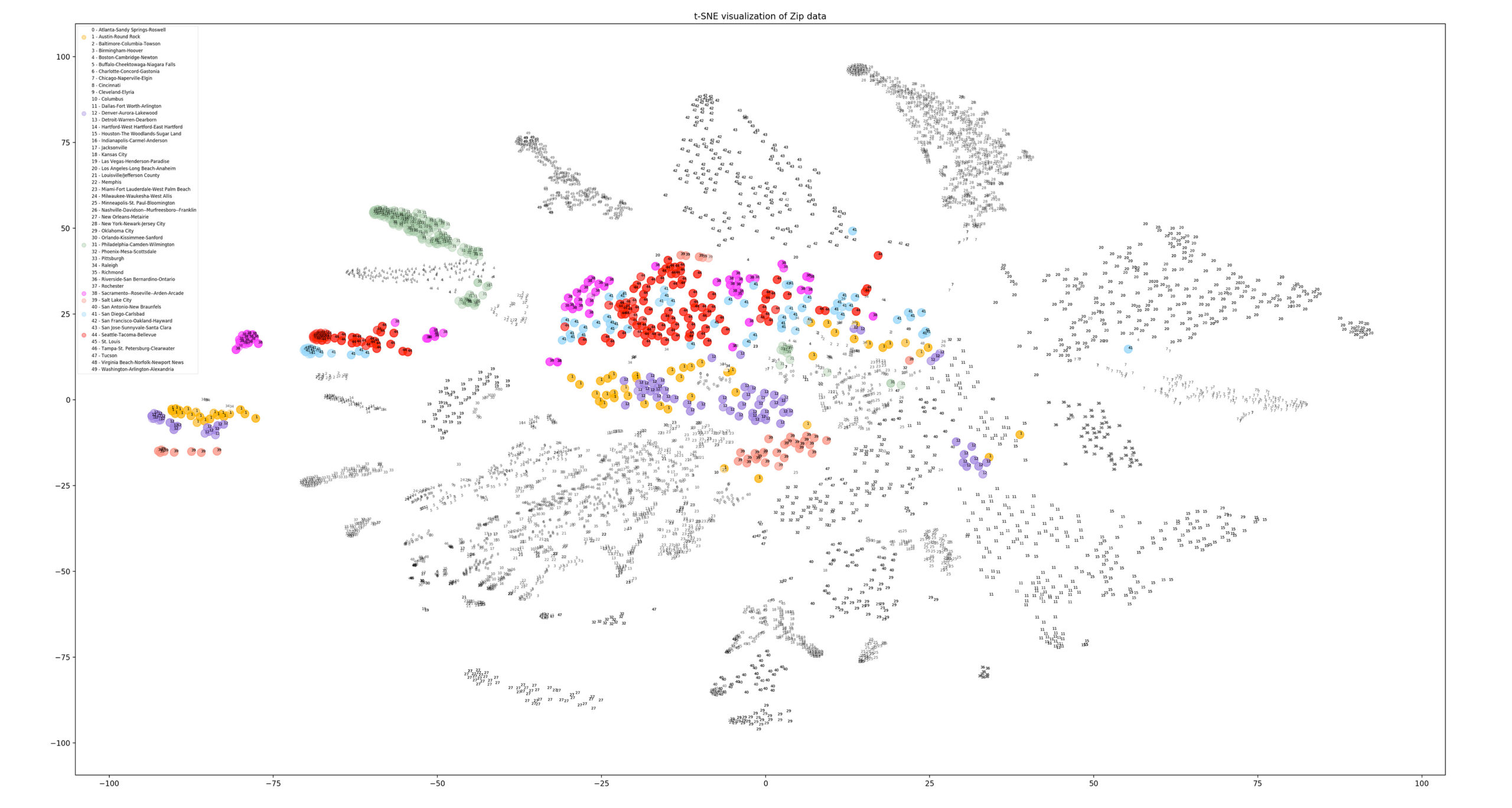
What is spatial intelligence?
For our purposes, it is data related to location. Spatial intelligence is applicable to any scale, from a room or a building to a city or a planet, and may range from the occupancy information of a single workstation to one’s global web of social-media connections. Human beings have amazing spatial intuition (we inhabit a range of spaces daily). But today’s plethora of data from devices and systems allows for even greater spatial understanding, with digital tools and scalable algorithms—including machine learning—allowing us to execute ever-more complex analyses and visualizations on the information. To demonstrate our point, we’ve leveraged these resources to show the process applied to an example question: Where might Amazon situate its second North American headquarters?